Evaluating Multi-turn Human-AI Conversations
Introduction
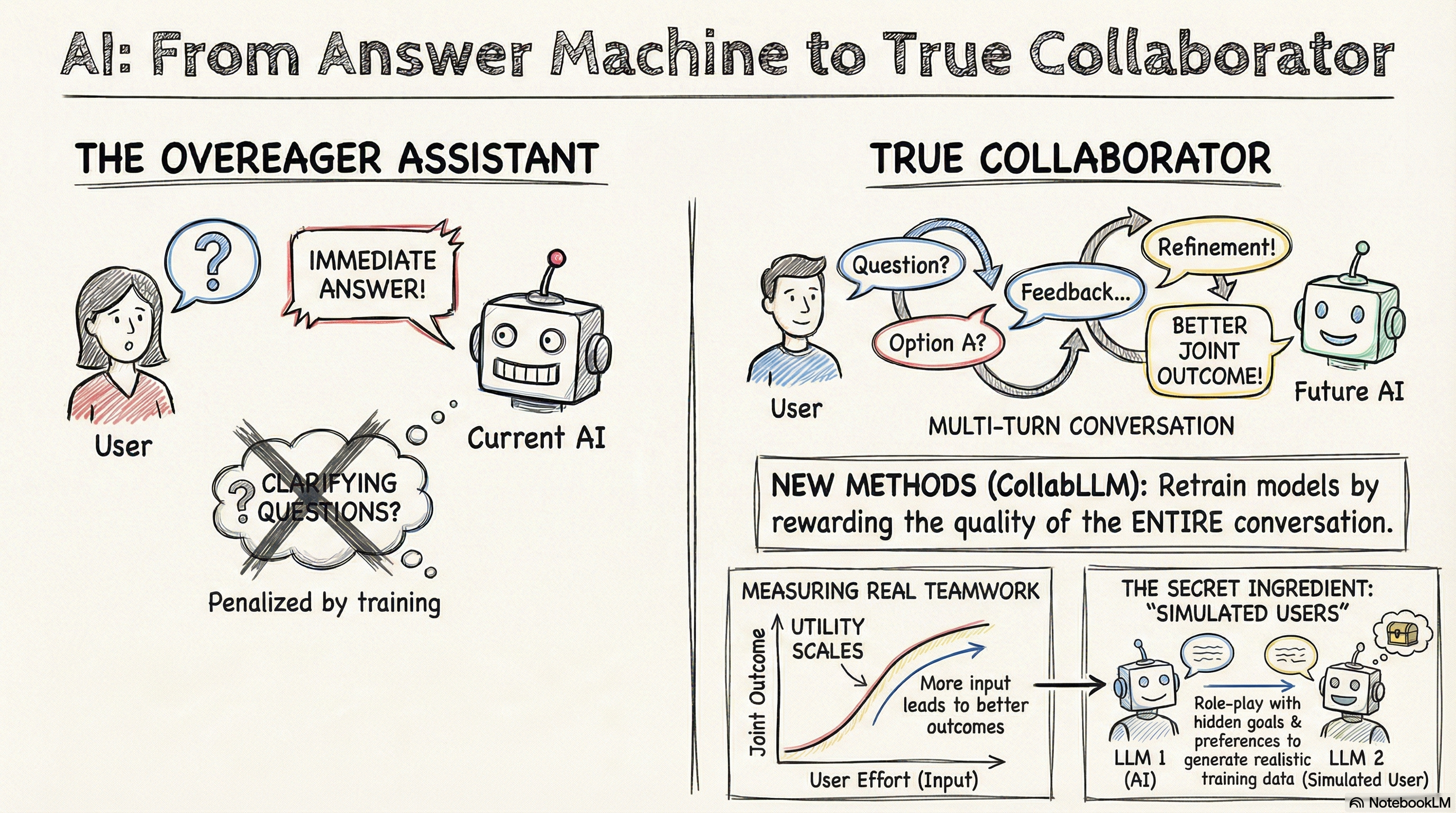
You’ve seen the demos: AI assistants that seemingly read minds, delivering perfect solutions in one shot. The hashtag might be #AGI, but the reality is, getting AI to help with any non-trivial tasks looks more like a conversation: with false starts, clarifying questions, and incremental refinements.
The limiting factor is not just model capability. It is human nature. We often do not know exactly what we want until we see what we do not want. And for exploratory problems, complete specification is often impossible from the start.
So how did AI labs evaluate AI’s ability to solve a problem with the user over multiple turns? They mostly did not, and the reason runs deeper than poor benchmark design. The bias is built into the post-training pipeline itself, which consists of two phases: Instruction Tuning and RLHF (Reinforcement Learning from Human Feedback).
Instruction tuning teaches a base language model, a powerful predictor of the next word from the preceding text, to generate answers to questions by showing the model many demonstration pairs of questions and answers. RLHF then reinforces this pattern: human annotators rate single responses in isolation, rewarding immediate solutions over follow-up or clarifying questions, since the human annotator would not see the potential positive impact of these kinds of responses downstream in the single-turn setup. This creates models trained to be overeager: optimized for answering, not for understanding what needs answering.
Researchers are now developing new methods to fill this gap, but they are coming at it from different angles. In the rest of the post, I go over my takeaways from reading two recent papers that illustrate this evolution:
CollabLLM
The CollabLLM team set out to correct the bias towards generating immediate answers introduced in the RLHF process. Specifically, they took an open weights model, Llama-3.1-8B-Instruct, which had gone through RLHF, and sought to improve its multi-turn conversation capabilities through a Reinforcement Learning process that explicitly rewards these capabilities.
To extend the single-turn paradigm used in RLHF, the CollabLLM team had to answer two critical questions:
How to generate realistic multi-turn conversations from an initial user prompt?
How to define what “good” looks like in a multi-turn conversation and make such constructs measurable?
CollabLLM’s answer to the first question is a technique called forward sampling. The core idea is to use a user simulator (i.e., another LLM instructed to play the role of the user) to synthetically generate the next few turns of the conversation with the Assistant LLM. Due to the cost-effective nature of the user simulator, the researchers could generate multiple forward samples from each starting point for evaluation.
With synthetic multi-turn data in hand, the researchers tackled the bigger challenge: teaching the model to value the future, not just the present. For each candidate assistant response, they use forward sampling to generate multiple possible conversation trajectories. They then score these full trajectories and average them—this is the Multiturn-aware Reward (MR). A response that leads to high-scoring futures gets a high MR, even if the response itself is just a clarifying question.
Specifically, the researchers defined a reward function consisting of two components:
Extrinsic metrics focused on goal achievement: These metrics are task-specific. For example, Pass Rate (PR) of the final code solution after the conversation is adopted for coding tasks.
Intrinsic metrics for assessing user experience: These metrics are task agnostic. The researchers employed two such metrics: Efficiency and Interactivity. Efficiency, measured by token count, penalizes unnecessarily long conversations, while Interactivity rewards specific collaborative behavior of the assistant, such as asking clarifying questions and guiding the user through a workflow.
With both the synthetic dataset and the metrics defined in MR, the team could now train models to optimize for multi-turn collaboration. But would this actually work with real humans?
To find out, the CollabLLM team ran a randomized controlled trial with 201 users through Amazon Mechanical Turk, asking them to write documents with anonymous AI assistants. Participants using the CollabLLM-powered assistant reported higher perceived quality of their final documents, better interaction experiences with their AI assistants, and even higher efficiency compared with participants using assistants powered by the base llama-3.1-8B-Instruct model. Even more telling: when the base model was specifically prompted to ask users clarifying questions, it still fell short. Users found it repetitive and inefficient, while CollabLLM produced more targeted, helpful interactions.
Completion ≠ Collaboration
While CollabLLM is focused on nudging the model to acquire collaboration skills in the post-training process, the “Completion ≠ Collaboration” paper is focused on evaluations outside of training. However, the motivations of these two projects are similar. The paper’s authors highlight a similar deficiency in existing benchmarks: they fail to measure the effectiveness of AI agents in inherently iterative, collaborative tasks with users. These domains include exploratory data analysis, financial advising, tutoring, and math research.
Let’s reconsider the two main obstacles in assessing human-AI collaboration: 1) the simulation of user contributions, and 2) the evaluation of collaborative effectiveness. How did this paper’s authors address these two issues?
Simulating User Turns
The authors leveraged a simulation environment called Collaborative Gym, where the agent being evaluated can engage in collaborative work with a simulated user powered by an LLM. The “gym” holds the state of the conversation between the two actors, passes the messages, and defines what actions are possible for the agent to take (e.g., “edit document,” “send message,” “search database,” etc).
In their experiment, the authors used gpt-4o to simulate the user in a travel planning scenario. The simulated user was prompted with additional details about the user’s preferences and goals, not fully disclosed to the agent at the first turn. In addition, the simulated user grades the agent actions at each turn on a 5-point scale on whether they are helping make progress towards the end goal. These grades are used to determine when the simulated user runs out of patience and terminates the conversation. The authors call this moment a “Usability Drop.”
Measuring Collaboration Quality
To make the quality of human-AI collaboration measurable, the authors proposed to focus on the relationship between two constructs: User Effort and Agent Utility. When the agent is a strong collaborator, its utility should scale as the user puts in more effort into the collaboration, a key idea illustrated in Figure 1 of the paper shown below. To operationalize the User Effort construct, the authors adopted a simple proxy of the number of human-led turns augmented by the number of tokens the human processes. Agent Utility is measured by the quality of the agent-generated artifact at each turn in a task specific manner.
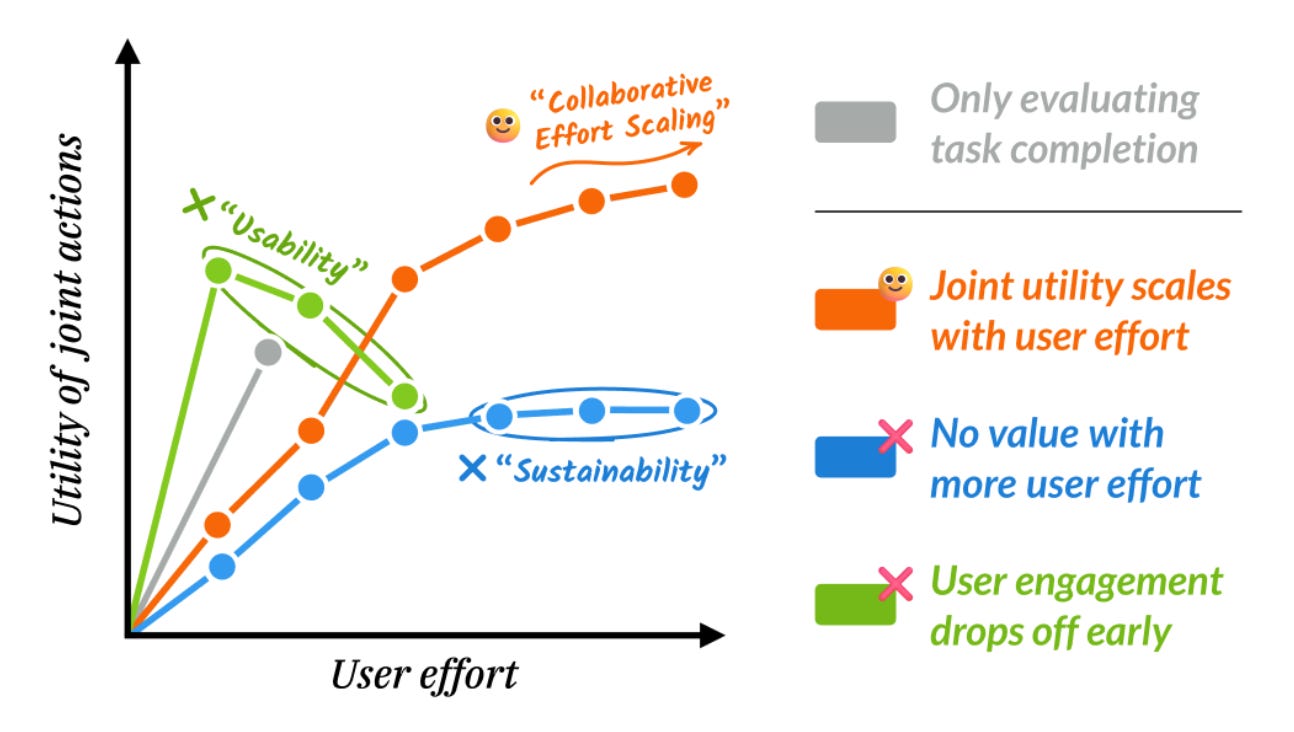
In a simulation-based experiment, the authors observed that two models in the Claude family were more effective in leveraging the additional effort made by the user than a few other models they tested. Furthermore, the authors pointed out an optimal range of agent-to-user effort ratios for different models where the utility of the agent peaks and then plateaus despite the simulated user putting in more effort.
Deep Dive into Simulated Users
A key “ingredient” in both papers is the user simulator for generating synthetic multi-turn data. Let’s take a closer look at how it works. In a nutshell, a user simulator is just another LLM instructed to role play a human user with a special prompt.
It’s not a complicated idea. Examining the prompts for the simulated user included in the appendix of these two papers reveal a few common elements:
The Persona: For example, “You are role-playing as a human USER interacting with an AI collaborator to complete a specific task.”
Hidden Information: The user simulator is given additional information about the task initially hidden from the agent and a reference answer used to assess the agent’s response. For example, the User Simulator in the “Completion ≠ Collaboration” paper was given the following additional information for a travel planning task:
[’Travel for 2 people’, ’Visit 2 cities in New York’, ’Preference for Mexican and Indian cuisine’, ’Budget of $6,300’]Conversation Guidelines: The user simulator is instructed to progressively specify the full task. For example, “As a user, avoid being too detailed in your responses. Provide vague or incomplete demands in the early stages of the conversation to minimize your effort.” This forces the agent to proactively seek clarification.
Prompting the LLM this way is intended to create a simulated user which progressively discloses the full task specification and its preferences to the agent.
The CollabLLM paper compared simulated and real users (crowdworkers on Amazon Mechanical Turk) to evaluate the approach’s effectiveness. The researchers noted several differences in behavior. Real users, for instance, exhibited less attention to grammar and frequently used shorter, more fragmented sentences than the simulated user. Furthermore, real users were less predictable, often unexpectedly shifting the conversation’s direction. Most revealingly, real users also expressed more emotion in their responses than the simulated user.
These behavioral differences show the limitations of this prompt-based user simulation approach. Because of these behavioral gaps, the field is already moving past simple prompts toward more sophisticated approaches such as fine-tuning an LLM based on real-world user responses (Wang et al., 2025; Naous et al., 2025).
Why, then, are we still relying on synthetic users? Ideally, we would train and evaluate on real-world production logs, which capture the true messiness of human behavior. However, production logs have a fatal flaw for research: they are static artifacts of the past. To truly evaluate a new collaborative assistant, we need the ability to explore multiple what-if scenarios: If the model had asked a clarifying question instead of answering, how would the user have responded? This need to explore counterfactual conversation trajectories is why dynamic simulators remain indispensable, despite their imperfections.
In Search of Better Metrics for Human-AI Communication
The quality of communication in both papers is measured using a mix of efficiency and experience metrics. These experience metrics were not formally defined; instead, their values were determined by an LLM acting as a judge, referred to as an “autorater.” For instance, the CollabLLM paper informally characterized a highly interactive assistant as follows:
The assistant is very engaging, asks all relevant questions, and significantly enhances understanding and problem-solving.
- Example: The assistant thoroughly understands the user’s question, asks for necessary clarifications, such as “It sounds like you’re asking about the causes of climate change. Are you looking for specific examples or a general overview?”A logical next step from such intuitively defined “experience” metrics is to draw from decades of research in human-to-human communications. One particular gift from this body of research is the Grounding in Communication theory developed by Clark and Brennan. The theory maintains that “all collective actions are built on common ground and its accumulation,” and it seeks to explain how it works through detailed conversation analysis.
Clark and Brennan (1991) proposed three key indicators of mutual understanding that should be considered when evaluating a conversation:
Acknowledgements: One participant explicitly affirms their understanding of the preceding turn.
Initiation of a relevant next turn: A participant demonstrates understanding by providing a response that is pertinent to the previous turn from the other party.
Continued attention: Non-verbal cues that signal a conversation partner’s sustained interest in the discussion’s content.
The theory has inspired researchers from Stanford University of Microsoft Research to develop a conversation analysis technique and apply it to evaluating multi-turn human-AI collaborations. In a recent paper, the researchers proposed a taxonomy of dialog acts to label each turn in a human-AI conversation (see Table 1 from the paper below), and then apply quantitative analysis over the labeled conversation data.

Looking Forward
Evaluating multi-turn human-AI conversations is challenging but critically important for the ongoing transition of AI assistants from being passive responders to active collaborators in solving increasingly more complex problems, which users often can’t fully specify at the beginning of the interaction.
Although recent efforts have begun to tackle key challenges, such as synthetically generating user turns and establishing metrics for high-quality conversations, there is a significant room for improvement. Researchers and practitioners trained in fields like Human-Computer Interaction (HCI) and Computer-Supported Cooperative Work (CSCW) are uniquely positioned to bridge these gaps. They can leverage the rich intellectual history of decades of research focused on human-to-human collaboration mediated by technology to make a substantial contribution to this area.
Great piece! Typo in reference? https://www.cs.cmu.edu/~illah/CLASSDOCS/Clark91.pdf ≠ Clark & Schaefer (1911)